
A 10-year reflection on interoperability, promises kept, and lessons learned
In October 2016, just before the ODI Summit in London, I was interviewed by Hannah Foulds, who at the time was working at the Open Data Institute (ODI).
She asked a deceptively simple question: how did I think the world would look in ten years’ time, as food and agriculture data became more digital, more accessible, and more widely shared.
My answer was simple — and ambitious:
“In 10 years I really hope that such information can be discoverable, machine-readable and interconnected.”
That sentence later became the informal title of the interview. Ten years on, it feels like the right moment to revisit it — not to score accuracy points, but to ask a more useful question:
What actually changed, and what did the last decade teach us about how progress really happens?

Where we started (2016)
In that interview, I described the starting point bluntly: food and agriculture information was fragmented, locked inside closed systems, and difficult to reuse across contexts.
That assessment was not controversial at the time — it was simply the reality. Most data lived in PDFs, spreadsheets, proprietary databases, or isolated portals. Discoverability was limited. Machine-readability was rare. Interconnection was the exception.
In hindsight, the core problem wasn’t lack of data. It was lack of connection.
What genuinely changed by 2026
Looking back from today, it would be unfair not to acknowledge real progress.
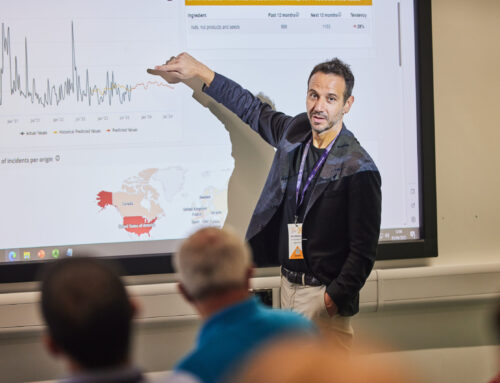
Across food safety and agriculture, APIs and open data portals are now common; digital traceability is mainstream rather than experimental; AI and analytics are part of everyday conversations; and the idea that publicly funded data is a shared asset is widely accepted.
Just as importantly, the culture shifted. Discussions around trust, governance, responsibility, and data stewardship — once niche — are now central. Leaders no longer debate whether data should be shared. They debate how, under what conditions, and to what end.
This mirrors what regulators such as Frank Yiannas have consistently emphasised in recent years: digital transformation in food safety is not about technology for its own sake, but about using data to move earlier — from reaction to prevention. That framing matters.

What didn’t change enough
And yet, one frustration remains stubbornly familiar. Despite better tools and more data, connecting information across systems is still harder than it should be.
The same recall, border rejection, or safety incident still looks different depending on where it is published. Hazards are structured in one system and buried in free text in another. Company identities fragment across borders. Dates, product categories, and semantics fail to align.
In other words, we digitised food safety — but we didn’t fully operationalise interoperability. This gap — between digitisation and usable intelligence — is now one of the main constraints on progress.
What the last decade clarified about interoperability
A recurring theme in regulatory, industry, and research discussions over the past few years is that interoperability is not primarily a technical problem.
Technology has largely caught up. APIs, cloud infrastructure, machine learning, and natural language processing are mature enough to support ambitious use cases. What hasn’t caught up at the same pace is agreement on shared meanings; governance of cross-system connections; and incentives to align rather than optimise locally.
This aligns with how many food-system and data leaders now describe the challenge: interoperability is a coordination and governance problem first — and a technical one second. That distinction explains why progress has been uneven, despite rapid technological advancement.
Why AI makes this unavoidable
In 2016, concerns about computing power and infrastructure were justified. In 2026, they are no longer the limiting factor.
AI is real. Analytics are operational. Horizon scanning, pattern detection, and predictive models are already in use across food safety and agriculture.
But here is the paradox increasingly acknowledged by AI leaders across sectors: AI does not fix fragmentation — it amplifies its consequences.
AI systems depend on data that is interpretable, aligned, and comparable across sources. When semantics drift, predictions lose meaning. When inputs are inconsistent, outputs become brittle or misleading.
So the central question today is no longer whether AI can transform food safety. It is whether our data ecosystems are ready to support AI without collapsing under their own inconsistencies.

©Phil Crow 2023
A closing reflection — and the question that follows
Ten years ago, a global, interconnected data ecosystem was a vision. Today, interoperability is an operational necessity.
And one lesson from the past decade stands out clearly:
progress does not come from forcing systems into one shape — it comes from connecting them through shared understanding.
That conclusion is no longer personal. It is increasingly shared across regulators, industry leaders, and data practitioners.
Which leads to a question I now hear more often than ever:
If interoperability is the goal, should we really be aiming for one global data standard — or is there a better way?
That is the question I will explore next.