
How can one monitor food fraud incidents around the world in almost real time? Can large-scale data analysis reveal patters related to the way that people modify food products, ingredients or packaging for economic gain? Is it possible to predict whether someone in the supply chain has substituted, misbranded, counterfeited, stolen or enhanced food in an unapproved way? In which ways can big data help us detect if there is increased probability of food fraud?
Let us assume that we have in our hands the world’s most comprehensive database of fraud-related incidents. This will probably include, among others:
- Food fraud incidents that have been officially announced by a governmental agency or inspection authority.
- Product or ingredient rejections at border customs because some type of adulteration has be found during an inspection.
- Lab test analyses that indicate that there has been a substitution or enhancement of a food for an economic purpose.
This would be a very large database about food fraud incidents that have already taken place. An interesting question then arises.
Can we mine a historical database of international food fraud to successfully predict what will happen in the future?
For instance, can we look into product or ingredient categories and try to identify emerging fraud types before they actually occur? Can we foresee and calculate the probability of having fraud incidents within a particular supply chain? Is it even possible to predict the specific time period during which this probability is very high, so that preventive measures can be taken?
What if we add more data in the mix? Is there a correlation between fraud incidents with price changes? Does the probability of fraud increase for suppliers based in countries with high corruption scores? Can a severe weather phenomenon be linked to an increase of food adulteration incidents in this area?

The food supply chain has many critical problems of this kind. People need to take decisions about whether risk exists. They need to know if a preventive action needs to be taken as early as possible. To do so, they rely on a large number and rich variety of data sources.
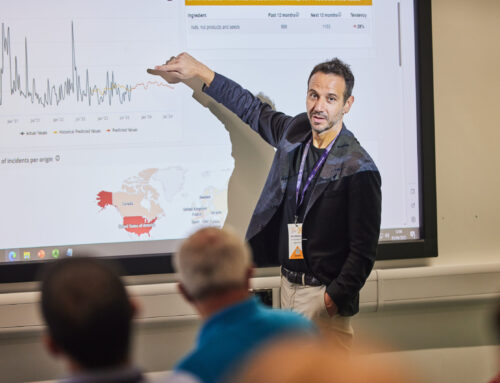
In our R&D project Big Data Grapes, we develop and test innovative solutions to such problems. These are designed as extensions to FOODAKAI, the premium food safety intelligence platform that serves large food processors, distributors and retailers from around the world.
After an open call to the food safety innovators in our network, a small industry focus group has been set up. We involve them in requirements’ collection, validation of new software features, testing ways in which candidate innovations may support critical decisions in their every day job. A new food fraud prediction dashboard for FOODAKAI is now under development, powered by the advanced processing and analytical capabilities that Agroknow’s big data platform offers.
We collaborate with the High Performance Computing Lab of CNR to extend the platform with machine learning algorithms that have been customised to predict food fraud. Together with the Human-Computer Interaction Research Group of KULeuven, we are investigating new types of dashboards that can represent uncertainty in a prediction using visual components that humans seem to understand (and trust) more. Working on the next release of our platform has become serious fun.