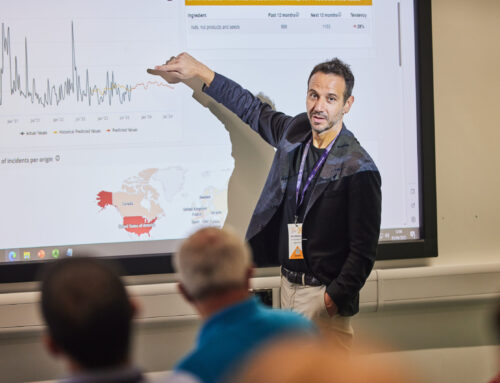

Let’s find ways to break down the data silos.
The food system is rapidly changing, becoming more and more digitized. Data is being generated about all food supply entities. It is critical to combine, process and extract meaning from all this data. To better understand emerging health threats. To predict and prevent risks before they occur.
As the FDA rightly points out, this includes steps such as:
- Explore methods to create public-private “data trusts,” a bank of large volumes of data generated by industry that can be accessed for analytical work to further strengthen preventive approaches.
- Find the balance between the need for transparency and concerns about the confidentiality of business data in advancing predictive analytics, including the development of protocols to establish that requests for data are targeted for a specific purpose.

(Photo by Thomas Jensen on Unsplash)
Agroknow has recently facilitated a Tech Panel on Predictive Analytics for Food Risk Prevention. We got together people from five tech companies that serve the food sector, discussed about the promise of predictive analytics, and then posed a difficult question:
How do we get everyone to share more data?
Let me highlight some of their suggestions that I found very interesting.
Michael Gibbons (VP Product & Co-Founder Provision Analytics)
I think the answer to that question is: “How do we incentivize the sharing of data between partners?”
In the carrot-vs-stick model, a carrot will always beat out the stick, having companies come to the table with a vested interest in sharing data, and a net benefit (through applicable cost reductions, or increases in profit from efficiencies), will be the key to beginning into that journey.
Brendan Ring (Commercial Director Creme Global)
The cases where we have had companies happy to share their data is when companies can use the output of the analysis to support regulatory submissions or to validate a proposition or claims they are making, whether it be to customers, regulators or the general public.
Also, where there is real advantage to be gained by viewing anonymized, aggregated data in order to identify trends that may exist, that they could not have picked up from their own internal testing only.
The wisdom of the masses as such. Even simply being able to confidentially view your own data in relation to where you fit with the overall industry can be very insightful for companies. So the barrier is not technology, it is the business value proposition.

(Photo by Chris Montgomery on Unsplash)
Giannis Stoitsis (CTO Agroknow)
First, we need to explain to all the stakeholders the value of having interconnected food safety data in the global supply chain and how this will help to reduce recalls that have a very significant impact on the public health and the food businesses.
Second, increase the confidence of the industry on the privacy issues, reassuring that there are mature technologies to enable anonymous and secure sharing of business-critical data.
Third, establish fair business models that will reward stakeholders that share data.
Finally, adopt data standards that will enable the exchange of food safety data generated throughout the supply chain.
Andrew Harrison (CTO Hazel Analytics)
This is a call to action: we need capable minds to step up and take the initiative to make this concept more of a working reality, from both technical and legal perspectives.
Ιdentify the source of confidentiality concerns (such as consumer privacy, legal liability, or access to financial details) and explore possible mitigations (such quantization of sensitive numerical data, robust anonymization of individuals, methods of withholding data without introducing skew, or practical policies and remedies) in order to build a proposal for data sharing that you can pitch to stakeholders.
Make it easy for someone to green-light the decision to share data; make them confident in the safety, simplicity, and value of doing so.

(Photo by Trevor Kay on Unsplash)
Let us continue this conversation. Let’s talk more about the ways in which private and public organizations may share more data of common interest and value. Let’s extend and evolve the work that existing groups (such as the Food Industry Intelligence Network – FiiN) are doing.
To build a more resilient, digital and interoperable food system.